Adopcja AI w eCommerce to przede wszystkim problem infrastruktury

Nowoczesny marketing powinien być prosty. 29 czerwca taki będzie.

W ciągu ostatnich kilku lat spędziłem sporo czasu na rozmowach o AI i jego rozwoju z zarządem, inwestorami, zespołami. Pytanie, które najczęściej pada podczas tych rozmów prawie zawsze jest to samo: „Kiedy AI zacznie robić za nas?”.
Moja odpowiedź również zawsze jest taka sama: szybciej niż myślisz, ale nie w taki sposób, jak to sobie wyobrażasz.
Widzę bowiem w naszej branży powtarzający się schemat: firmy inwestują w potencjał AI, a potem zastanawiają się, dlaczego to nie dowozi wyników. Modele są solidne. Case’y są dobrze zdefiniowane. A mimo to wyniki utykają na etapie pilotażu, nigdy nie docierając do klientów na szeroką skalę.
Problem prawie nigdy nie leży w samym modelu. Leży w tym, co go podtrzymuje.

Modele AI są, pod wieloma względami, tą łatwiejszą częścią całego procesu. Trudność z adopcją polega na zbudowaniu platformy, która będzie w stanie rzetelnie karmić je danymi, uruchamiać je z odpowiednią prędkością, dbać o ich dokładność w czasie i mierzyć realny wpływ na biznes.
Większość platform eCommerce powstała w innych czasach – zostały zaprojektowane tak, aby niezawodnie obsługiwać transakcje i raportować wyniki po fakcie. To po prostu nie działa w handlu napędzanym przez AI, który wymaga danych w czasie rzeczywistym, podejmowania decyzji „w locie” i infrastruktury, która wytrzyma taką presję bez spowalniania systemu.
Kiedy próbujesz nałożyć AI na platformę, która nie została do tego stworzona, kończysz z czymś, co wygląda imponująco na prezentacji demo, ale rozczarowuje w warunkach produkcyjnych. I szczerze mówiąc, to wyzwanie, o którym obecnie najczęściej słyszę od moich kolegów po fachu.
Zanim porozmawiamy o modelach, musimy porozmawiać o danych, a konkretnie o tym, jak bardzo pofragmentowane są dane o klientach w większości organizacji.
Klient może trafić do Ciebie przez płatną reklamę w social mediach, przeglądać ofertę na telefonie, a sfinalizować zakup na komputerze trzy dni później. W wielu platformach są to trzy rozłączone rekordy. Nie ma ujednoliconej tożsamości i nie ma ciągłości.
Ta fragmentacja jest zabójcza dla AI. Silniki rekomendacji, modele przewidywania odejść (churn), personalizacja w czasie rzeczywistym – wszystko to zależy od spójnego obrazu tego, kim jest klient i co zrobił. Bez tego karmisz swoje modele niekompletnymi danymi i zastanawiasz się, dlaczego wyniki nie są wiarygodne.
Techniczną odpowiedzią jest zszycie tych oddzielnych rekordów w jeden: połączenie ciasteczek, identyfikatorów urządzeń, adresów e-mail i loginów do kont w jeden trwały profil klienta. Brzmi to prosto, ale w praktyce jest to świadoma decyzja projektowa na poziomie architektury – coś, czego nie da się „dokleić” po fakcie.
Raport McKinsey stawia sprawę jasno: 71% konsumentów oczekuje spersonalizowanych doświadczeń, a firmy, które dowożą je skutecznie, mogą zwiększyć przychody z personalizacji nawet o 40%. Ale nie możesz personalizować czegoś, czego nie widzisz.
Jedną ze zmian, o których myślę najczęściej, jest przejście od analityki wsadowej (batch) do handlu w czasie rzeczywistym. Brzmi to jak zwykła aktualizacja, ale w rzeczywistości to zupełnie inny sposób myślenia o całej infrastrukturze danych.
Tradycyjne potoki danych (pipelines) projektowano tak, by zbierać dane i przetwarzać je później. Ten model sprawdza się w przypadku raportów generowanych o wyznaczonym czasie, np. rano. Nie działa jednak, gdy klient aktywnie przegląda Twoją stronę, a Twój silnik rekomendacji wciąż serwuje mu sygnały z wczoraj.
Architektura, ku której zmierzamy, traktuje każde kliknięcie, wyszukiwanie czy aktualizację koszyka jako sygnał, na który cała platforma reaguje natychmiast. Kafka i podobne platformy streamingowe są kręgosłupem tego podejścia – tkanką łączną, która synchronizuje każdą część platformy.
Mówiąc prościej: Twoja platforma przestaje być systemem ewidencji, a zaczyna być systemem reakcji. Zachowanie klienta staje się daną wejściową „na żywo”, a nie historycznym raportem.
Gdy Twoja platforma odpowiada w danym momencie, klienci to zauważają – i zauważają to też Twoje przychody. Wymaga to jednak celowych inwestycji w infrastrukturę. To nie dzieje się przez przypadek.
Oto szczegół techniczny, który zasługuje na więcej uwagi w rozmowach na szczeblu zarządu: luka między tym, jak model zachowuje się w testach, a tym, jak działa w świecie rzeczywistym.
Dzieje się tak, gdy dane, na których model był trenowany, różnią się od danych, które otrzymuje „na żywo” na produkcji. Model zachowuje się inaczej w testach, a inaczej w rzeczywistości – ta różnica jest często niewidoczna, dopóki nie zaczniesz drążyć, dlaczego wydajność spadła.
Rozwiązaniem jest Feature Store: scentralizowany system zarządzający sygnałami używanymi przez modele uczenia maszynowego, zapewniający spójność między środowiskiem treningowym a produkcyjnym. Zamiast sytuacji, w której każdy zespół niezależnie oblicza własną wersję sygnałów o kliencie, takich jak aktualność zakupów, powinowactwo do kategorii czy przewidywana wartość życiowa (LTV), istnieje jedno wspólne źródło, z którego korzystają wszyscy.
Takie podejście rzadko trafia na posty na LinkedIn, ale z mojego doświadczenia wynika, że to jeden z największych wyróżników między AI, które się skaluje, a takim, które tego nie potrafi.
Ujednolicona warstwa danych i Feature Store tworzą fundament, ale wciąż potrzebują nowoczesnego stosu infrastruktury. I tu widzę, że wiele organizacji niedoszacowuje stopnia złożoności.
Handel napędzany przez AI to nie tylko przetwarzanie dużych wolumenów danych. To robienie tego przy jednoczesnym reagowaniu na interakcje klienta w milisekundach. Ta kombinacja skali i prędkości wyklucza większość legacy architektury i wskazuje jasno na nowoczesną infrastrukturę, gdzie każdy element może rosnąć lub kurczyć się niezależnie, nie obciążając reszty.
W praktyce taki stos technologiczny wygląda zazwyczaj tak:
Na warstwie przechowywania: platformy obiektowe, jak Amazon S3 czy Azure Data Lake, trzymają surowe zbiory danych do analityki i trenowania modeli – to Twój fundament historyczny. Obok nich hurtownie danych, takie jak Snowflake, BigQuery czy Redshift, obsługują analityczne zapytania na dużą skalę.
Do przetwarzania w czasie rzeczywistym: infrastruktura streamingowa – z najpopularniejszą Kafką – dystrybuuje zdarzenia behawioralne do usług w momencie, gdy się dzieją.
Dla danych szybkiego dostępu: bazy o niskich opóźnieniach, jak Redis czy DynamoDB, przechowują dane sesyjne i cechy klienta tak szybko, że klient nigdy nie musi czekać.
Serwowanie modeli: wdrażanie wytrenowanych modeli jako mikrousługi (przy użyciu TensorFlow Serving, TorchServe czy KServe). Łączą się one bezpośrednio z Twoim sklepem lub narzędziami marketingowymi, czyniąc AI żywą funkcją wplecioną w platformę, a nie osobnym narzędziem działającym obok.
Zasadą architektoniczną wiążącą to wszystko jest niezależna skalowalność. Gdy ruch gwałtownie rośnie podczas wyprzedaży flash sale lub szczytu sezonowego, każda warstwa elastycznie dopasowuje się do potrzeb. Twoje procesy AI działają dalej. Rekomendacje są serwowane. Twoi klienci nic nie zauważają.
Ale nawet świetny stos technologiczny nie zagwarantuje dokładności modeli. Do tego potrzeba czegoś więcej.
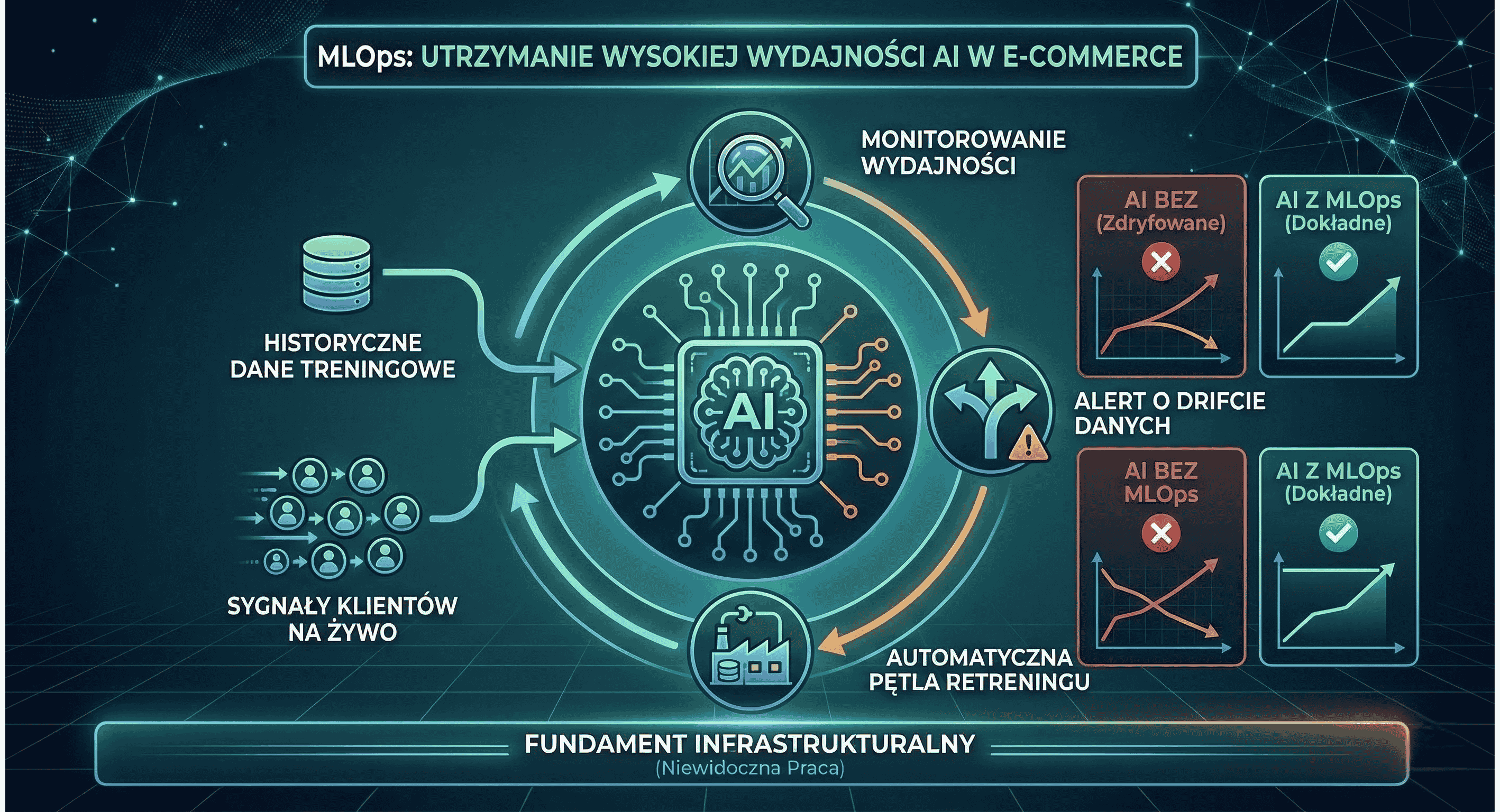
Wdrożenie modelu to kamień milowy. Utrzymanie go to prawdziwa praca.
Zachowania klientów się zmieniają. Warunki rynkowe ewoluują. Model wytrenowany sześć miesięcy temu mógł być wtedy dokładny, a teraz po cichu podaje błędne wyniki – nie dlatego, że coś się zepsuło, ale dlatego, że świat, na którym się uczył, nie pasuje już do świata, w którym operuje. Nazywa się to data drift (dryf danych) i jeśli pozostanie niewykryte, po cichu niszczy wartość, którą tak ciężko budowałeś.
Dlatego MLOps – dyscyplina operacyjna wokół systemów uczenia maszynowego – to coś, co umieściłbym w agendzie strategicznej każdego CTO w eCommerce. Obejmuje automatyczne monitorowanie modeli, potoki ponownego trenowania, benchmarking wydajności i ostrożny proces testowania zmian na małej grupie użytkowników przed ich pełnym wdrożeniem.
Wytyczne Google dotyczące architektury ML są tu jasne: budowanie automatycznych mechanizmów kontrolnych i ciągły monitoring nie są opcjonalnym dodatkiem – to one sprawiają, że całość działa rzetelnie.
Firmy, które traktują MLOps jako kluczową kompetencję inżynieryjną, a nie dodatek, to te, którym inwestycja w AI się zwraca. Reszta ciągle tylko gasi pożary.
Chcę poruszyć temat, który czasem bywa traktowany jako formalność prawna, a nie kwestia strategiczna: prywatność.
Badania Salesforce wykazały, że 73% klientów oczekuje od firm zrozumienia ich indywidualnych potrzeb – ale jednocześnie 71% twierdzi, że chroni swoje dane osobowe bardziej niż kiedykolwiek. To nie jest sprzeczność. To sygnał, jak wygląda zaufanie w 2026 roku.
Z perspektywy architektury oznacza to, że prywatności nie da się „doinstalować”. Zarządzanie zgodami, anonimizacja danych, ścisła kontrola dostępu, obsługa danych zgodna z RODO – to musi być wmurowane w fundamenty.
Perspektywiczne podejście mówi, że privacy-by-design to nie tylko zarządzanie ryzykiem. To przewaga konkurencyjna. Klienci, którzy Ci ufają, dzielą się większą liczbą sygnałów. Więcej sygnałów to lepsze modele. Lepsze modele to bardziej trafne doświadczenia. To pozytywne sprzężenie zwrotne – ale tylko wtedy, gdy masz fundament, by je udźwignąć.
Najważniejsza zmiana, jaką widzę w kwestii adopcji AI dla eCommerce, nie dotyczy samych modeli, ale infrastruktury wokół nich, która staje się w pełni „real-time” na każdym etapie.
Obecnie nawet dobrze zaprojektowane platformy mają opóźnienia w różnych punktach: zbieranie danych, obliczanie cech, wnioskowanie modelu, dostarczenie odpowiedzi. W ciągu najbliższych kilku lat spodziewam się, że najbardziej konkurencyjne platformy znacząco zniwelują te luki, idąc w stronę architektur, w których inteligentne decyzje zapadają w milisekundach w każdym punkcie styku z klientem.
To oznacza, że decyzje infrastrukturalne podejmowane dzisiaj, takie jak sposób projektowania potoków danych, wdrażania modeli i zarządzania cechami, bezpośrednio określą pozycję konkurencyjną za trzy do pięciu lat.
Firmy traktujące AI jako dodatek będą wciąż odbijać się od tej samej ściany. Te, które potraktują to jako dyscyplinę architektoniczną, wysuną się na prowadzenie.
Jeśli miałbym zostawić Cię z jedną myślą, byłoby to:
Zanim zapytasz, co AI powinno zrobić dla Twojego biznesu, zapytaj, czy Twoja platforma jest gotowa, by je obsłużyć.
W praktyce oznacza to cztery filary:
Ujednoliconą warstwę danych klientów z realnym łączeniem tożsamości.
Streaming zdarzeń, który czyni zachowanie klienta daną „na żywo”, a nie historyczną.
Feature Store i nowoczesny stos technologiczny zapewniający spójność modeli i skalowalność.
Praktyki MLOps, które dbają o dokładność i niezawodność AI w czasie.
Zadbaj o te fundamenty, a AI stanie się czymś, co faktycznie zyskuje na wartości wraz z upływem czasu, poprawia się z każdą interakcją klienta, adaptuje się do zmian i dostarcza personalizację, która realnie buduje zaufanie.
Pomiń je, a będziesz w kółko uruchamiać pilotaże, które nigdy nie wyjdą poza fazę testów.
To, w moim odczuciu, jest najważniejsze pytanie strategiczne, które każdy CTO w eCommerce powinien sobie dzisiaj zadać.
Coś jest nie tak z marketingowym softwarem.I żeby było jasne: problemem nie jest sam marketing. Wystarczy spojrzeć na dzisiejszych marketerów, kompetentnych, pracujących na danych i ambitniejszych niż kiedykolwiek wcześniej. Problem tkwi w narzędziach, które miały ich wspierać w pracy, a nie dotrzymują im kroku. Przeszkadzają, zamiast pomagać.

Wpisz w Google „jaki procent programów lojalnościowych kończy się porażką", a otrzymasz rozpiętość wyników większą niż Andy – i to po obu stronach. Zależnie od źródła, liczby wahają się od 20% do nawet 97%. To mówi nam dwie rzeczy. Po pierwsze: nikt tak naprawdę nie wie, co oznacza „porażka". Po drugie: cała masa programów lojalnościowych po prostu nie dowo...

Znasz ten slajd. Ten, na którym Twoja marka znajduje się w samym środku, a kanały komunikacji rozchodzą się na zewnątrz jak szprychy koła. E-mail, SMS, web push, social media, płatne reklamy, personalizacja na stronie, a jeśli mierzysz wysoko – może nawet program lojalnościowy....